protected void Button1_Click(object sender, EventArgs e)
{
string path = MapPath("XMLFile.xml");
XmlDocument xmldoc = new XmlDocument();
xmldoc.Load(path);
XmlElement newelement = xmldoc.CreateElement("poems");
XmlElement xmlauthor = xmldoc.CreateElement("author");
XmlElement xmltitle = xmldoc.CreateElement("title");
XmlElement xmlcontent = xmldoc.CreateElement("content");
xmlauthor.InnerText = TextBox1.Text.ToString();
xmltitle.InnerText = TextBox2.Text.ToString();
xmlcontent.InnerText = TextBox3.Text.ToString();
newelement.AppendChild(xmlauthor);
newelement.AppendChild(xmltitle);
newelement.AppendChild(xmlcontent);
xmldoc.DocumentElement.AppendChild(newelement);
xmldoc.Save(path);
}
Tuesday, May 11, 2010
Tuesday, April 20, 2010
TOP Nth SALARY IN SQLSERVER2005
Top Second Salary :-
Top Third Salary :-
select top 1 salary from employee where salary in (select top 3 salary from employee order by salary desc ) order by salary
Just change the value in Inner Query(2,3,4.........)
Tuesday, April 6, 2010
Difference between for and foreach loop in c#
The for loop executes a statement or a block of statements repeatedly until a specified expression evaluates to false. there is need to specify the loop bounds( minimum or maximum).
int j = 0;
for (int i = 1; i <= 5; i++)
{
j = j + i ;
}
The foreach statement repeats a group of embedded statements for each element in an array or an object collection.you do not need to specify the loop bounds minimum or maximum.
int j = 0;
int[] tempArr = new int[] { 0, 1, 2, 3, 5, 8, 13 };
foreach (int i in tempArr )
{
j = j + i ;
}
int j = 0;
for (int i = 1; i <= 5; i++)
{
j = j + i ;
}
The foreach statement repeats a group of embedded statements for each element in an array or an object collection.you do not need to specify the loop bounds minimum or maximum.
int j = 0;
int[] tempArr = new int[] { 0, 1, 2, 3, 5, 8, 13 };
foreach (int i in tempArr )
{
j = j + i ;
}
Thursday, April 1, 2010
Transact-SQL Optimization Tips
This can results in good performance benefits, because SQL Server will return to client only particular rows, not all rows from the table(s). This can reduce network traffic and boost the overall performance of the query.
This can results in good performance benefits, because SQL Server will return to client only particular columns, not all table's columns. This can reduce network traffic and boost the overall performance of the query.
This can reduce network traffic, because your client will send to server only stored procedure or view name (perhaps with some parameters) instead of large heavy-duty queries text. This can be used to facilitate permission management also, because you can restrict user access to table columns they should not see.
SQL Server cursors can result in some performance degradation in comparison with select statements. Try to use correlated subquery or derived tables, if you need to perform row-by-row operations.
Because SELECT COUNT(*) statement make a full table scan to return the total table's row count, it can take very many time for the large table. There is another way to determine the total row count in a table. You can use sysindexes system table, in this case. There is ROWS column in the sysindexes table. This column contains the total row count for each table in your database. So, you can use the following select statement instead of SELECT COUNT(*): SELECT rows FROM sysindexes WHERE id = OBJECT_ID('table_name') AND indid < 2 So, you can improve the speed of such queries in several times.
See this article for more details:
Constraints are much more efficient than triggers and can boost performance. So, you should use constraints instead of triggers, whenever possible.
Table variables require less locking and logging resources than temporary tables, so table variables should be used whenever possible. The table variables are available in SQL Server 2000 only.
The HAVING clause is used to restrict the result set returned by the GROUP BY clause. When you use GROUP BY with the HAVING clause, the GROUP BY clause divides the rows into sets of grouped rows and aggregates their values, and then the HAVING clause eliminates undesired aggregated groups. In many cases, you can write your select statement so, that it will contain only WHERE and GROUP BY clauses without HAVING clause. This can improve the performance of your query.
Because using the DISTINCT clause will result in some performance degradation, you should use this clause only when it is necessary.
This can reduce network traffic, because your client will not receive the message indicating the number of rows affected by a T-SQL statement.
This can improve performance of your queries, because the smaller result set will be returned. This can also reduce the traffic between the server and the clients.
You can quickly get the n rows and can work with them, when the query continues execution and produces its full result set.
The UNION ALL statement is much faster than UNION, because UNION ALL statement does not look for duplicate rows, and UNION statement does look for duplicate rows, whether or not they exist.
Thursday, March 25, 2010
connection string syntax
The database connection string is passed to the necessary object during object instantiation or set via a property or method. The format of a connection string is a semicolon-delimited list of key/value parameter pairs.
example in C# that shows how to connect to SQL Server with the creation of a SqlConnection object :-
string cString = "Data Source=server;Initial Catalog=db;User ID=test;Password=test;";
SqlConnectionconn = new SqlConnection();
conn.ConnectionString = cString;
conn.Open();
VB.NET version:-
Dim cString As String
cString = "Data Source=server;Initial Catalog=db;User ID=test;Password=test;"
Dim conn As SqlConnection = New SqlConnection()
conn.ConnectionString = cString
conn.Open()
The connection string specifies the database server and database, along with the necessary username and password to access the database. While this format isn't appropriate for all database interactions, it does have a number of available options; many of the options have synonyms.
Along with the Data Source, Initial Catalog, User ID, and Password elements, the following options are available:
- Application Name: The name of the application. If not specified, the value is .NET SqlClient Data Provider.
- AttachDBFilename/extended properties/Initial File Name: The name of the primary file, including the full path name, of an attachable database. The database name must be specified with the keyword database.
- Connect Timeout/Connection Timeout: The length of time (in seconds) to wait for a connection to the server before terminating. The default value is 15.
- Connection Lifetime: When a connection is returned to the pool, its creation time is compared with the current time. The connection is destroyed if that time span (in seconds) exceeds the value specified by connection lifetime. The default value is zero.
- Connection Reset: Signals whether a connection is reset when removed from a pool. A false valid negates an additional server round-trip when obtaining a connection. The default value is true.
- Current Language: The SQL Server Language record name.
- Data Source/Server/Address/Addr/Network Address: The name or network address of the instance of SQL Server.
- Encrypt: When true, SQL Server uses SSL encryption for all data sent between the client and server if the server has a certificate installed. Recognized values are true, false, yes, and no.
- Enlist: Signals whether the pooler automatically enlists the connection in the creation thread's current transaction context. The default value is true.
- Database/Initial Catalog: The database name.
- Integrated Security/Trusted Connection: Signals whether Windows authentication is used to connect to the database. It may be set to true, false, or sspi, which is equivalent to true. The default value is false.
- Max Pool Size: The maximum number of connections allowed in the pool. The default value is 100.
- Min Pool Size: The minimum number of connections allowed in the pool। The default value is zero। OR
- Network Library/Net: The network library used to establish a connection to an instance of SQL Server. Supported values include dbnmpntw (Named Pipes), dbmsrpcn (Multiprotocol/RPC), dbmsvinn (Banyan Vines), dbmsspxn (IPX/SPX), and dbmssocn (TCP/IP). The protocol's DLL must be installed to properly connect. The default value is TCP/IP.
- Packet Size: The size of the network packets (in bytes) used to communicate with the database. The default value is 8192.
- Password/Pwd: The account name's corresponding password.
- Persist Security Info: Determines whether security information is available once a connection has been established. A true value says security-sensitive data like the username and password are available, whereas false says it is not. Resetting the connection string resets all connection string values including the password. The default value is false.
- Pooling: Determines if connection pooling is utilized. A true value says the connection is drawn from the appropriate pool, or if necessary, is created and added to the appropriate pool. The default value is true.
- User ID: The account name used to log on the database.
- Workstation ID: The name of the workstation connecting to SQL Server. The default value is the local computer's name.
The following connection string connects to the Northwind database on the Test\Dev1 server using a trusted connection and the specified logon (the less than secure blank administrator password) credentials:
Server=Test\Dev1;Database=Northwind;User ID=sa;
Password=;Trusted_Connection=True;
The next connection string used TCIP/IP and a specific IP address:
Data Source=192.162.1.100,1433;Network Library=DBMSSOCN;
Initial Catalog=Northwind;User ID=sa;Password=;
The options used are easy to include in the connection string, but they will depend upon your application and its requirements. It is good to know what is available, so you can use it appropriately.
Monday, February 15, 2010
Insert data from gridview to database (ASP.NET)
using System;
using System.Web.UI.WebControls;
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
foreach (GridViewRow row in gvTest.Rows)
{
CheckBox box = row.FindControl("cbChecked") as CheckBox;
}
}
protected void btnCGo_Click(object sender, EventArgs e)
{
// Never give a button click event any more responsibility that capturing the click event :)
GetInformationToSave();
}
///
/// Gets the information to save.
///
protected void GetInformationToSave()
{
foreach (GridViewRow row in gvTest.Rows)
{//This condition is added since here we are inserting only the rows which are checked
CheckBox checkbox = (CheckBox)row.FindControl("cbChecked");
// Collect your information below if the checkbox is checked...
if (checkbox.Checked)
{
Label lblFirstName = (Label)row.FindControl("lblFirstName");
Label lblLastName= (Label)row.FindControl("lblLastName");
//After all your information, send to method that is responsible for saving data to databasea
SaveToDatabase(lblFirstName.Text.Trim(), lblLastName.Text.Trim());
}
}
}
///
/// Saves to database.
///
/// The first name.
/// The last name.
protected void SaveToDatabase(string firstName, string lastName)
{
// CODE HERE TO SAVE TO DATABASE. OBVIOUSLY THIS METHOD SHOULD NOT BE IN THE PAGE CODE BEHIND BUT JUST HERE
// TO DEMONSTRATE.
}
}
using System.Web.UI.WebControls;
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
foreach (GridViewRow row in gvTest.Rows)
{
CheckBox box = row.FindControl("cbChecked") as CheckBox;
}
}
protected void btnCGo_Click(object sender, EventArgs e)
{
// Never give a button click event any more responsibility that capturing the click event :)
GetInformationToSave();
}
///
/// Gets the information to save.
///
protected void GetInformationToSave()
{
foreach (GridViewRow row in gvTest.Rows)
{//This condition is added since here we are inserting only the rows which are checked
CheckBox checkbox = (CheckBox)row.FindControl("cbChecked");
// Collect your information below if the checkbox is checked...
if (checkbox.Checked)
{
Label lblFirstName = (Label)row.FindControl("lblFirstName");
Label lblLastName= (Label)row.FindControl("lblLastName");
//After all your information, send to method that is responsible for saving data to databasea
SaveToDatabase(lblFirstName.Text.Trim(), lblLastName.Text.Trim());
}
}
}
///
/// Saves to database.
///
/// The first name.
/// The last name.
protected void SaveToDatabase(string firstName, string lastName)
{
// CODE HERE TO SAVE TO DATABASE. OBVIOUSLY THIS METHOD SHOULD NOT BE IN THE PAGE CODE BEHIND BUT JUST HERE
// TO DEMONSTRATE.
}
}
Friday, December 4, 2009
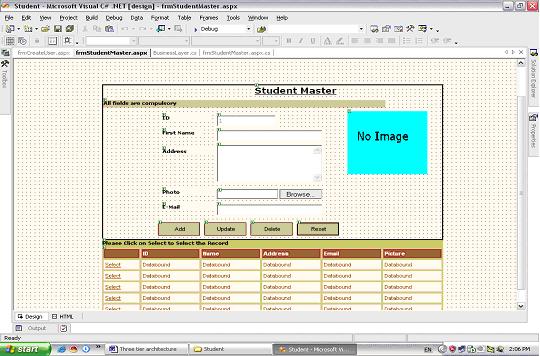
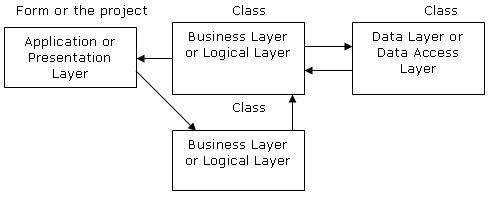
Three Tier Architecture in ASP.NET
3-tier application is a program which is organized into three major disjunctive tiers on layers। Here we can see that how these layers increase the reusability of codes.
For More Information:- http://www.beansoftware.com/ASP.NET-Tutorials/Three-Tier-Architecture.aspx
These layers are described below.
1. Application layer or Business layer
2. Business layer
a. Property layer(Sub layer of business layer)
3. data layer
Advantages of three Tier Architecture.
The main characteristic of a Host Architecture is that the application and databases reside on the same host computer and the user interacts with the host using an unfriendly and dump terminal. This architecture does not support distributed computing (the host applications are not able to connect a database of a strategically allied partner). Some managers found that developing a host application take too long and it is expensive. Consequently led these disadvantages to Client-Server architecture.
Client-Server architecture is 2-Tier architecture because the client does not distinguish between Presentation layer and business layer. The increasing demands on GUI controls caused difficulty to manage the mixture of source code from GUI and Business Logic (Spaghetti Code). Further, Client Server Architecture does not support enough the Change Management. Let suppose that the government increases the Entertainment tax rate from 4% to 8 %, then in the Client-Server case, we have to send an update to each clients and they must update synchronously on a specific time otherwise we may store invalid or wrong information. The Client-Server Architecture is also a burden to network traffic and resources. Let us assume that about five hundred clients are working on a data server then we will have five hundred ODBC connections and several ruffian record sets, which must be transported from the server to the clients (because the Business layer is stayed in the client side). The fact that Client-Server does not have any caching facilities like in ASP.NET, caused additional traffic in the network. Normally, a server has a better hardware than client therefore it is able compute algorithms faster than a client, so this fact is also an additional pro argument for the 3.Tier Architecture. This categorization of the application makes the function more reusable easily and it becomes too easy to find the functions which have been written previously. If programmer wants to make further update in the application then he easily can understand the previous written code and can update easily.
Application layer or Presentation layer
Application layer is the form which provides the user interface to either programmer of end user. Programmer uses this layer for designing purpose and to get or set the data back and forth.
Business layer
This layer is a class which we use to write the function which works as a mediator to transfer the data from Application or presentation layer data layer. In the three tier architecture we never let the data access layer to interact with the presentation layer.
a. Property Layer
This layer is also a class where we declare the variable corresponding to the fields of the database which can be required for the application and make the properties so that we can get or set the data using these properties into the variables. These properties are public so that we can access its values.
Data Access Layer
This layer is also a class which we use to get or set the data to the database back and forth. This layer only interacts with the database. We write the database queries or use stored procedures to access the data from the database or to perform any operation to the database.Summary
Application layer is the form where we design using the controls like textbox, labels, command buttons etc.
Business layer is the class where we write the functions which get the data from the application layer and passes through the data access layer.
Data layer is also the class which gets the data from the business layer and sends it to the database or gets the data from the database and sends it to the business layer.
Property layer is the sub layer of the business layer in which we make the properties to sent or get the values from the application layer. These properties help to sustain the value in a object so that we can get these values till the object destroy.
Data flow from application layer to data layer
You can download sample three tier project, used for this tutorial. Here we are passing the code of the student to the business layer and on the behalf of that getting the data from the database which is being displayed on the application layer.
Presentation Layer:
private void DataGrid1_SelectedIndexChanged(object sender, System.EventArgs e)
{
// Object of the Property layer
clsStudent objproperty=new clsStudent();
// Object of the business layer
clsStudentInfo objbs=new clsStudentInfo();
// Object of the dataset in which we receive the data sent by the business layer
DataSet ds=new DataSet();
// here we are placing the value in the property “ID†using the object of the
property layer
objproperty.id=int.Parse(DataGrid1.SelectedItem.Cells[1].Text.ToString());
// In ths following code we are calling a function from the business layer and passing the object of the property layer which will carry the ID till the
database.
ds=objbs.GetAllStudentBsIDWise(objproperty);
// What ever the data has been returned by the above function into the dataset is
being populate through the presentation laye.
txtId.Text=ds.Tables[0].Rows[0][0].ToString();
txtFname.Text=ds.Tables[0].Rows[0][1].ToString();
txtAddress.Text=ds.Tables[0].Rows[0][2].ToString();
txtemail.Text=ds.Tables[0].Rows[0][3].ToString();
Image1.ImageUrl=ds.Tables[0].Rows[0][4].ToString();
}
Property Layer
// These are the properties has been defined in the property layer. Using the object of the property layer we can set or get the data to or from these properties.
public class clsStudent // Class for Student Table
{
private int _id;
private string _Name;
private string _Address;
private string _Email;
private string _Picture;
public int id // Property to set or get the value into _id variable
{
get{return _id;}
set{_id=value;}
}
public string Name
{
get{return _Name;}
set{_Name=value;}
}
public string Address
{
get{return _Address;}
set{_Address=value;}
}
public string Email
{
get{return _Email;}
set{_Email=value;}
}
public string Picture
{
get{return _Picture;}
set{ _Picture=value;}
}
}
Business Layer:
"Obj" is the object of the clsStudent class has been defined in the property layer. This function is receiving the property object and passing it to the datalayer class
// this is the function of the business layer which accepts the data from the application layer and passes it to the data layer.
public class clsStudentInfo
{
public DataSet GetAllStudentBsIDWise(clsStudent obj)
{
DataSet ds=new DataSet();
ds=objdt.getdata_dtIDWise(obj);// Calling of Data layer function
return ds;
}
}
Datalayer Layer
// this is the datalayer function which is receiving the data from the business layer and
performing the required operation into the database
public class clsStudentData // Data layer class
{
public DataSet getdata_dtIDWise(clsStudent obj) // object of property layer class
{
DataSet ds;
string sql;
sql="select * from student where StudentId="+obj.id+" order by StudentId";
ds=new DataSet();
// this is the datalayer function which accepts trhe sql query and performs the
corresponding operation
ds=objdt.ExecuteSql(sql);
return ds;
}
}
For More Information:- http://www.beansoftware.com/ASP.NET-Tutorials/Three-Tier-Architecture.aspx
Subscribe to:
Posts (Atom)